Lesson 6: Lists, lists, lists and applying functions with purrr
Functions for Lesson 6
map, pluck, keep, discard, compact
Packages for Lesson 6
dplyr, purrr
Agenda
Use the purrr package to apply functions to lists and vectors.
Cheat sheet for the purrr package.

Do First
Recreate the below plot using the smaller NYC Airbnb dataset. The curve is a 'loess'. To change the legend title, add the (unintuitive) colour = "your legend title" argument to the labs() function.
# smaller csv file (16 cols)
url <- "http://data.insideairbnb.com/united-states/ny/new-york-city/2021-04-07/data/listings.csv.gz"
nyc <- readr::read_csv(url)
nyc <- nyc[nyc$id < 1e+06, ] # get smaller subet of data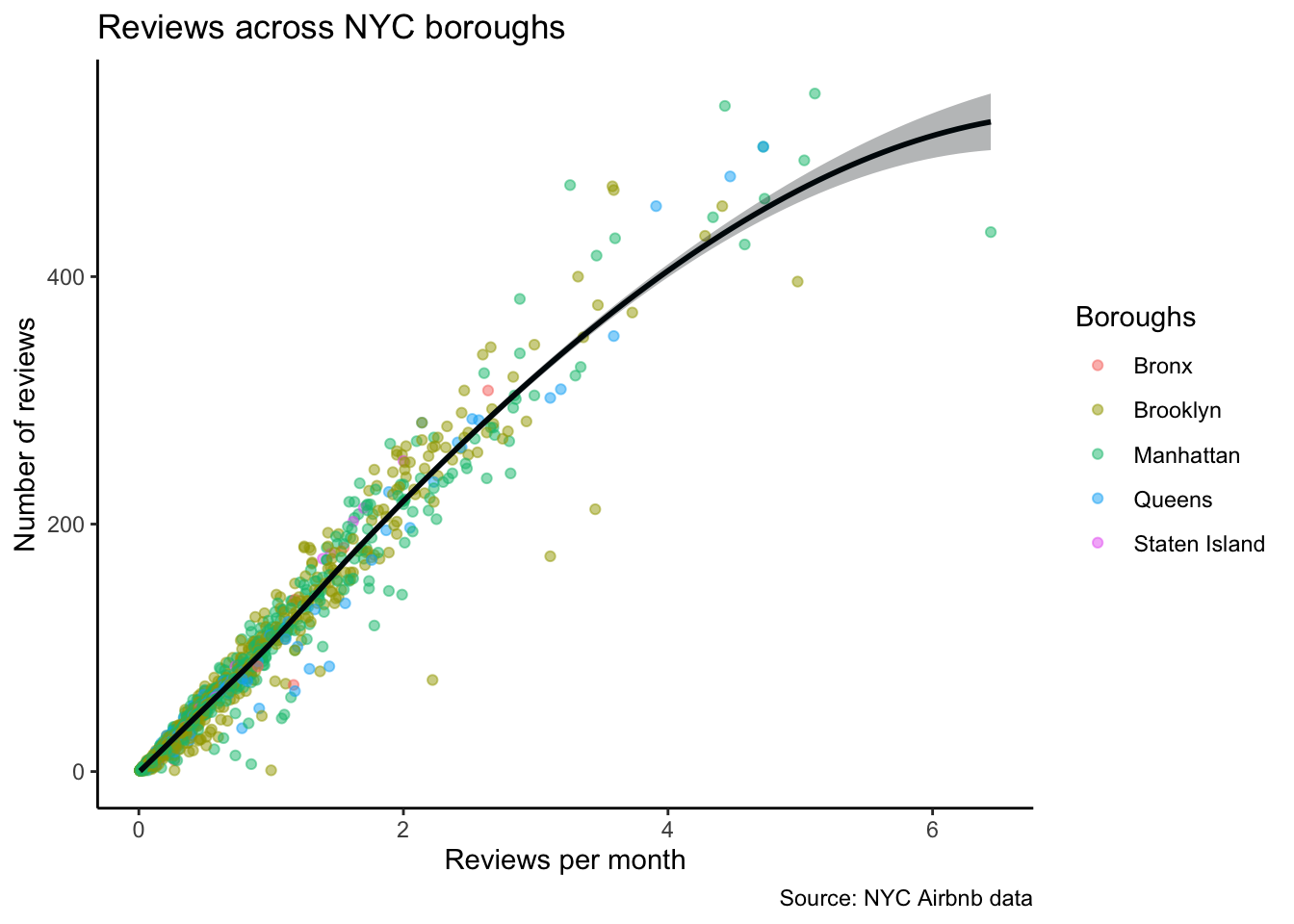
Create some data in a list
First generate some random data
s1 <- sample(10) # random number sample
s2 <- rnorm(10, 500) # sample 10 normally distributed random numbers around a mean of 500
s3 <- runif(10) # random uniform distribution
s1 [1] 2 4 1 8 10 5 3 6 7 9s2 [1] 501.6309 498.4540 499.8142 501.0258 499.9049 499.9875 499.9702 502.5944 501.3363 498.4851s3 [1] 0.8834566 0.1607566 0.8669604 0.1298742 0.4734379 0.9133809 0.2103161 0.3419445 0.2215991
[10] 0.3468892Now combine these into a list using list()
ls1 <- list(s1, s2, s3) # create a list of these data
ls1[[1]]
[1] 2 4 1 8 10 5 3 6 7 9
[[2]]
[1] 501.6309 498.4540 499.8142 501.0258 499.9049 499.9875 499.9702 502.5944 501.3363 498.4851
[[3]]
[1] 0.8834566 0.1607566 0.8669604 0.1298742 0.4734379 0.9133809 0.2103161 0.3419445 0.2215991
[10] 0.3468892ls1 %>% strList of 3
$ : int [1:10] 2 4 1 8 10 5 3 6 7 9
$ : num [1:10] 502 498 500 501 500 ...
$ : num [1:10] 0.883 0.161 0.867 0.13 0.473 ...Exercise 0
List indexing
Print the ls1 list object and take note of the index and elements
ls1
# index
ls1[1]
ls1[2]
ls1[3]
# elements
ls1[[1]][[1]]
ls1[[1]][[3]]
ls1[[2]][[10]]
ls1[[3]][[11]] # ??
ls1[[3]] %>% length
# what's the difference?
ls1[1]
ls1[[1]]Apply functions
The purrr package uses the following apply functions to apply function iteratively to a list or vector.
map Apply a function to each element of a list
require(purrr)
set.seed(12) # set a number seed to generate reprodicible results for random data
map(ls1, mean) # get the mean Exercise 1
Apply summary stats to the ls1 list data
* sum
* summary
* max
* sqrt
* length and lengths
What happens when you run the following and why?
mean(ls1)
sum(ls1)
Exercise 2
Filter lists
pluck Select an element by name or index
keep Select elements that pass a logical test
discard Select elements that do not pass a logical test
compact Drop empty elements
pluck(ls1, 3) # advantage = returns numeric
ls1[3][[1]] # this is the same as above
func <- map(ls1, mean) > 10 # create a logical test (a predicate function)
keep(ls1, func)
discard(ls1, func)
ls2 <- list(1, NA, NULL, integer(0), list()) # list of empty and null things
compact(ls2)Store plots in lists for easy retrieval. Create two plots of the ls1 data (called ls1p and ls2p) and store in a list called plot_list.
First turn the list into a dataframe so ggplot understands it.
ls1_df <- ls1 %>% data.frame
names(ls1_df) <- c("A", "B", "C")plot_list <- list(ls1p, ls2p)Plot your plot from the object plot_list
Exercise 3
Summarise lists
every Do all elements pass a test?
some Do some elements pass a test?
has_element Does a list contain an element?
detect Find first element to pass
detect_index Find index of first element to pass
vec_depth Return depth (number of levels of indexes)
ls1 %>% every(is.character)
ls1 %>% some(is.character)
ls1 %>% has_element("foo")
ls1 %>% detect(is.character)
ls1 %>% detect_index(is.character)
ls1 %>% vec_depthExercise 4
Transform lists
modify Apply function to each element
modify_at Apply function to elements by name or index
modify_if Apply function to elements that pass a test
modify_depth Apply function to each element at a given level of a list
ls1_repeat <- list(list(list(ls1))) # create list of lists
ls1_repeat %>% map(mean) # list is indexed too far down
ls1_repeat %>% modify_depth(4, mean) # access deep list indices Further useful purrr functions
pmap Apply a function to groups of elements from lists of lists
lmap Apply function to each list-element of a list or vector
imap Apply function to each element of a list or vector and its index