Lesson 10: Scraping webpage data and text
Functions for Lesson 10
read_html,html_node,html_nodes, html_attr, html_text, html_table
Packages for Lesson 10
rvest,xml2,magick,magrittr
Reading webpage data (HTML)
Reading webpage data can save a ton of time and space by avoiding the need to download the data to your drive and read it into R manually.
Rather than pulling the entire webpage, specify HTML elements (nodes), such as headings, tables, images to scrape.
Use html_node to get only the first HTML node and html_nodes to pull all elements. This is useful when you want to grab just the first element or all data associated with that node, e.g. within a table.
require(rvest)
require(xml2)
require(dplyr)
url <- "https://r4ds.had.co.nz/data-visualisation.html" # url to scrape
url %>% rvest::read_html() # scrape HTML text and data
# scraping the first node only for third order headings ('h3')
url %>% read_html %>% html_node("h3") # get only first section heading
# scraping all nodes in the webpage
url %>% read_html %>% html_nodes("h3") # get section headings
url %>% read_html %>% html_nodes("img") # get just imagesWrite a simple function to pull the HTML node you're interested in
node <- function(n) {
url %>% read_html %>% html_nodes(n) # n = user defined node
}Pull specific text, such as headings using HTML elements, i.e. <h1>, <img>, etc
node("h1") # get first order headings
# now pull just the text without the HTML elements
node("h2") %>% html_text(trim = T)
node("strong") %>% html_text(trim = T) # get just bold text Find and pull all unique R functions from the webpage and view the first 10 results
node("code") %>% html_text(trim = T) %>% unique %>% head(10)
If you're unsure what node to call, right click on the piece of data/text you want from the webpage and click "Inspect". Here, you can identify the HTML element you need.
E.g. I want just the quotes from the page, but don't know what type of node they belong to. After inspecting the element, we can see it's called a 'blockquote'.
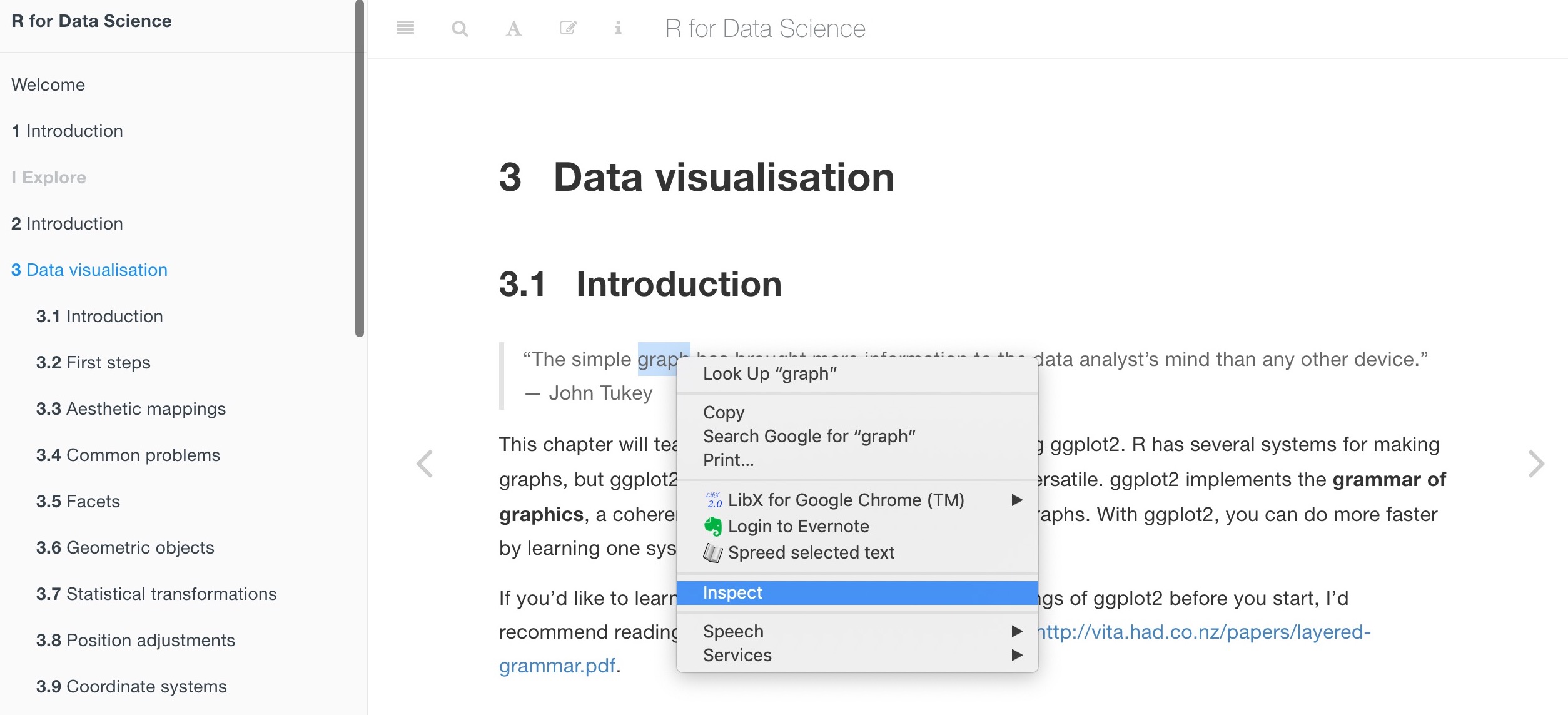
node("blockquote") %>% html_text(trim = T)Scrape table data
url <- "https://www.imdb.com/title/tt0094625/?ref_=fn_al_tt_1"
url %>% read_html %>% html_table(trim = T) # get just tablesFinding and scraping specific attributes within a webpage
Let's say you wanted to scrape all the urls within a webpage, but ignore the urls contained within some parts of the page, e.g. the sidebar or footer.
We can use html_attr() to identify nested elements within HTML elements.
This code scrapes the urls from the below webpage, but inclues all possible urls, which is not what we want.
url <- "https://r4ds.had.co.nz/index.html"
# first we see what type of attributes are available for urls ('a' tags)
node("a") %>% html_attrs() %>% head
node("a") %>% head(20) # return first 20 resultsSpecifying the main body of the webpage ("main") solves this, but we still want just the urls. Using html_attr() gives us just the url portion of the HTML link element (<a>)
node("main") %>% html_nodes("a") %>% html_attr("href") %>% head(20) # return first 20 resultsIf you wanted just the text associated with the links and not the link themselves, just pull the text instead of using html_attr()
node("main") %>% html_nodes("a") %>% html_text() %>% head(20) # return first 20 resultsTo pull a value/term from a webscraped vector, you can use extract2() from the magrittr package to specify the position in the vector
require(magrittr)
node("main") %>%
html_nodes("a") %>%
extract2(3) %>% # get the 3rd scraped term
html_text() Alternatively, you can index the term
require(rvest)
node("main") %>%
html_nodes("a") %>%
.[[3]] %>% # get the 3rd scraped term
html_text()
# to return a range/sequence
node("main") %>%
html_nodes("a") %>%
.[3:6] %>% # get range
html_text() Alternative method using xml
You can also search for nodes and attributes using xpaths (XML), if that's your thing.
The string convention is './/
require(xml)
# find all XML returning 'a' tags
url %>% read_html() %>% xml_find_all(".//a")
# find the first XML returning 'list'
url %>% read_html() %>% xml_find_first(".//li")Plotting images directly from webpages
Use image_read() from the magick package to plot images directly after scraping from a webpage
require(magick)
node("img") %>% html_attr("src") %>% image_read()More functions
Challenge
Find and scrape the image from the below url and plot it, all without leaving R or saving the img to your drive.
url <- "https://www.imdb.com/title/tt0094625/?ref_=fn_al_tt_1"